

{kind=link}
Okay, let’s talk about something I fiddled with recently – the humble string. Seems basic, right? But wow, getting a good handle on manipulating strings can really make a difference. I want to share a little journey I went through that reminded me just how powerful strings can be when you know how to wrestle with them.
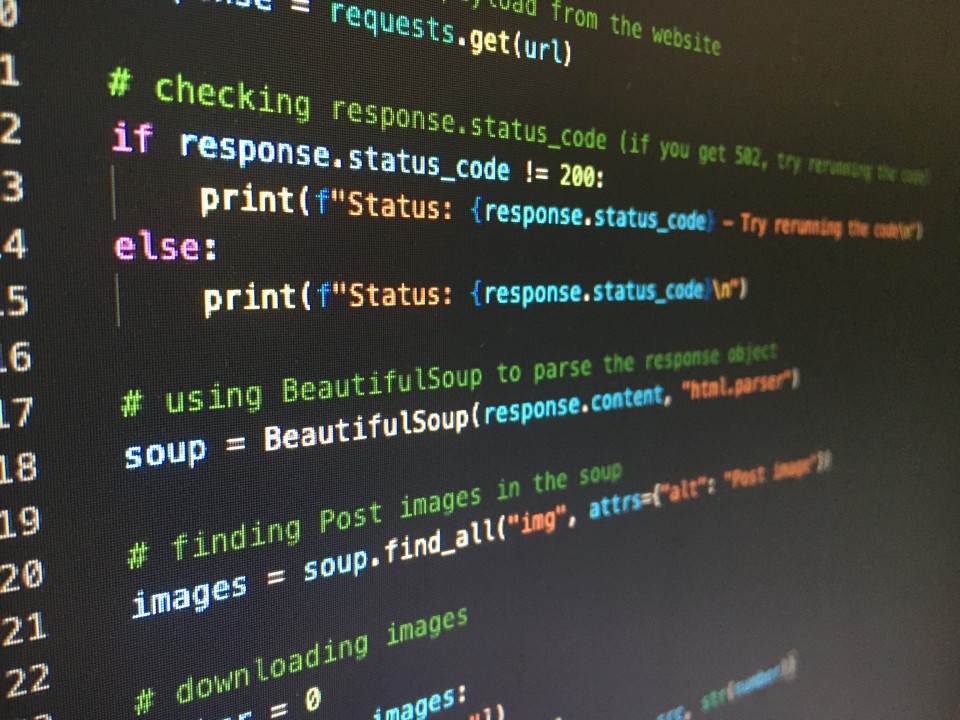
My Little String Challenge
So, picture this: I had a bunch of text data dumped into several files. It wasn’t nicely formatted like a database table, oh no. It was more like a collection of random notes, logs, maybe user comments jumbled together. Some lines had useful bits of information I needed, like reference numbers or specific keywords, buried amongst a lot of noise. My task was to pull out only the lines containing a specific pattern, let’s say lines starting with “ID:” followed by a number.
My first thought was, okay, easy peasy. I’ll just read the file line by line. For each line, I’ll check if it starts with “ID:”. That’s a simple string check. Seemed straightforward enough.
Well, I fired up my editor and wrote a quick script. Read a line, use a basic “startsWith” check, and if it matches, print the line. I ran it on the first file. Okay, got some results. But then I looked closer. Some lines started with spaces before “ID:”, so my simple check missed them. Oops. Other lines had “Id:”, lowercase ‘d’. Missed those too. And some files were huge, and just reading line-by-line felt a bit clunky when I realised the data wasn’t consistent.
Time for Plan B. I realized I needed to be a bit more flexible. Just checking the absolute start wasn’t cutting it. I needed to handle variations.
- First, I decided to clean up each line before checking it. I used a trim function to chop off any leading or trailing spaces. That fixed the problem with lines starting with spaces.
- Next, for the case variation (“ID:” vs “Id:”), I converted the beginning part of the trimmed line to uppercase before comparing it. So, I’d grab the first 3 characters, make them uppercase, and then check if they equalled “ID:”. That caught both variations.
- Then I thought about the actual extraction. I didn’t just want the line, I wanted the number after “ID:”. So, after confirming a line was a match, I needed to get the rest of the string. I found the position of the colon “:”, and then used a substring function to grab everything after it.
- More cleaning! Sometimes the number had spaces around it, like “ID: 123 “. So, after extracting the part after the colon, I used trim again on that extracted number string to get just “123”.
It was a process, you know? Read, trim, check the start ignoring case, if it matches, find the colon, grab the rest, trim that part too. It felt like I was sculpting the data, chipping away the unwanted bits.

Putting these steps together, iterating through each line, applying these string manipulations – trimming, changing case for comparison, finding character positions, extracting substrings – it finally worked reliably across all the messy files. It wasn’t the most elegant code perhaps, but it was practical and got the job done.
So yeah, that’s my little story. Strings might seem trivial, but knowing how to properly slice, dice, clean, and compare them is super important. It turned a frustrating task with messy data into something manageable. Never underestimate the power of string handling skills – they’re fundamental tools in the box!